

AWS (Amazon Web Services) S3 Multipart Upload é uma funcionalidade que permite fazer upload de grandes objetos (ficheiros) para o Amazon Simple Storage Service (S3) em partes mais pequenas, ou “pedaços”, e depois montá-los do lado do servidor para criar o objeto completo.
Este processo oferece várias vantagens em relação aos uploads tradicionais de uma única vez:
- Resiliência: os multipart uploads são mais robustos, pois reduzem as hipóteses de falhas de upload. Se uma parte não for uplodaded, só precisamos de tentar novamente o upload dessa parte específica, em vez de fazermos upload do ficheiro inteiro;
- Desempenho: os multipart uploads permitem a paralelização da transferência de dados, melhorando a velocidade geral de upload, especialmente para ficheiros grandes;
- Pausa e retoma: podemos pausar e retomar multipart uploads, o que é útil quando existem ligações de rede instáveis, ou quando o upload demora muito tempo;
- Utilização otimizada da memória: os multipart uploads permitem o upload de partes de forma independente, reduzindo a quantidade de memória necessária no lado do cliente para lidar com ficheiros grandes;
- Streaming de objetos: permite a transmissão de dados diretamente da fonte para o S3, sem necessidade de armazenar todo o objeto na memória.
Para iniciar um multipart upload, temos de criar um novo pedido de multipart upload com a API S3 e, de seguida, fazer upload de partes individuais do objeto em chamadas separadas à API, cada uma identificada por um número de parte único.
Assim que todas as partes forem uploaded, o multipart upload é concluído e o S3 reunirá as partes para formar o objeto final. Além disso, é possível abortar um multipart upload em qualquer altura para limpar quaisquer partes uploaded e poupar nos custos de armazenamento.
Os multipart uploads são normalmente utilizados quando se trata de ficheiros com mais de 100 MB, ou quando se preveem condições de rede instáveis durante o processo de upload.
Este artigo pretende ilustrar as vantagens dos multipart uploads do AWS S3 de uma forma detalhada e prática, fornecendo uma implementação através do Dropzone.js e do framework Flask do Python, juntamente com o AWS S3 boto3 Python SDK.
O lado do servidor
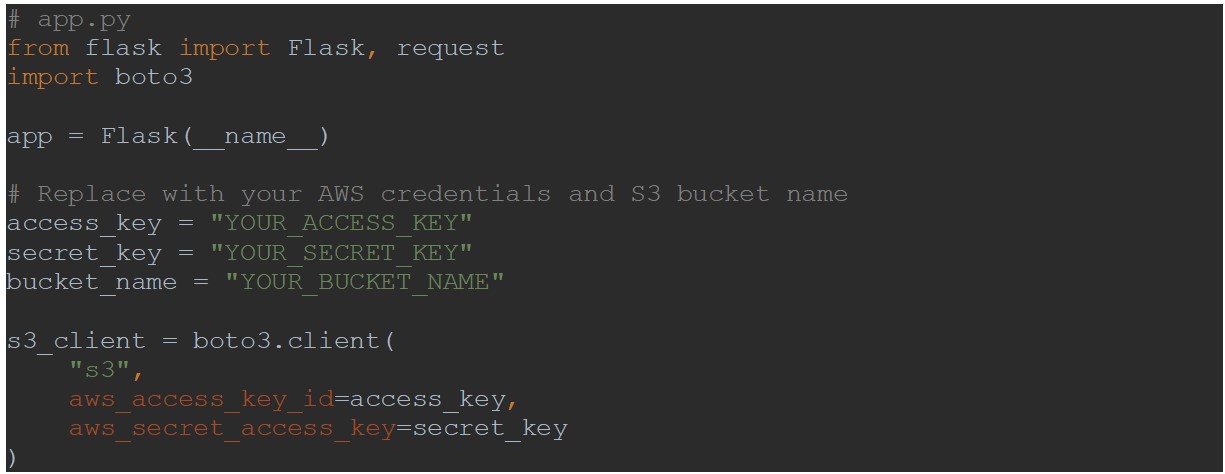
Por motivos de segurança, os pedidos ao S3 são feitos via proxy por meio de uma API restful do Flask. Vamos começar por criar e configurar a aplicação Flask:
De seguida, vamos criar três endpoints do Flask para as seguintes funcionalidades:
- Iniciar o upload de multipartes do S3 e recuperar o respetivo ID de upload;
- Fazer upload das partes do ficheiro, ou ficheiros inteiros quando não são suficientemente grandes para serem divididos em pedaços;
- Concluir o multipart upload.
Iniciar o Endpoint do Multipart Upload
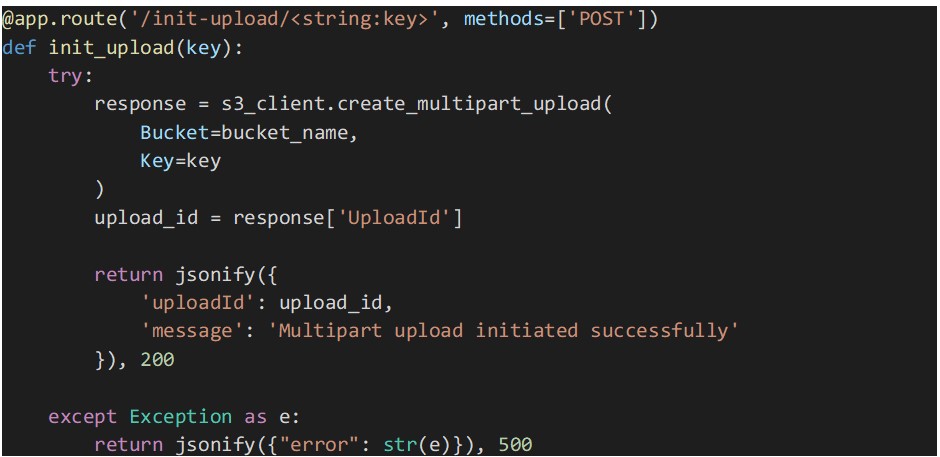
A implementação do endpoint abaixo inicia um multipart upload para o bucket S3 especificado e a chave de objeto através do SDK Boto3.
A função “create_multipart_upload” é chamada para criar um novo multipart upload, e o “UploadId” retornado pela API é incluído na resposta.
Upload de ficheiro endpoint
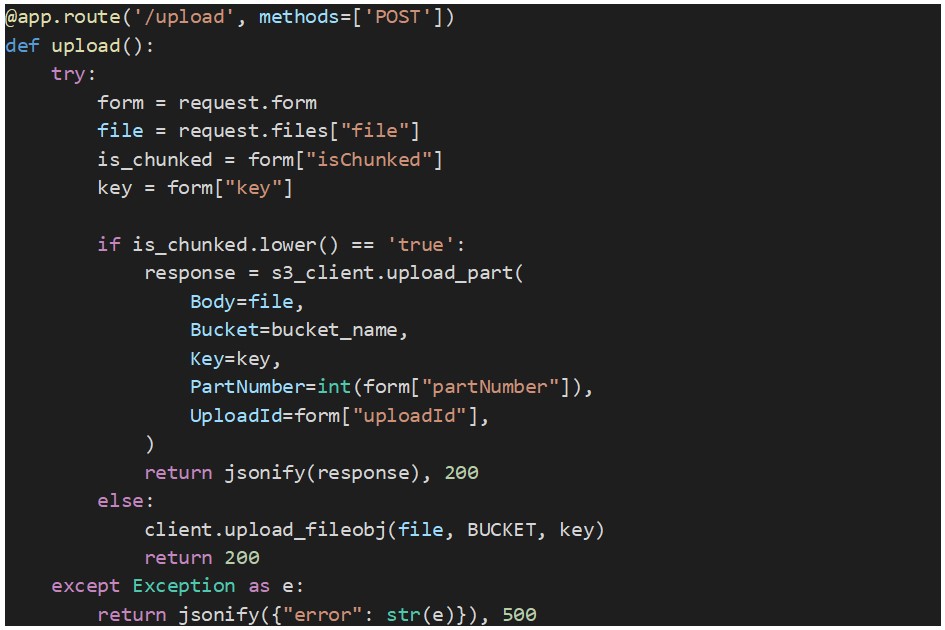
Este endpoint recebe um ficheiro, ou uma parte de um ficheiro, como informação bináriá juntamente com a chave de objeto S3, o ID de upload (obtido a partir do método “create_multipart_upload”), o número da parte (número único para cada parte a partir de 1) e um sinalizador que indica se o upload é de uma parte de ficheiro ou de um ficheiro inteiro.
A parte é uploaded para o S3 utilizando o método “upload_part”. Abaixo encontra-se o código fonte para este endpoint:
Completar o endpoint do Multipart Upload
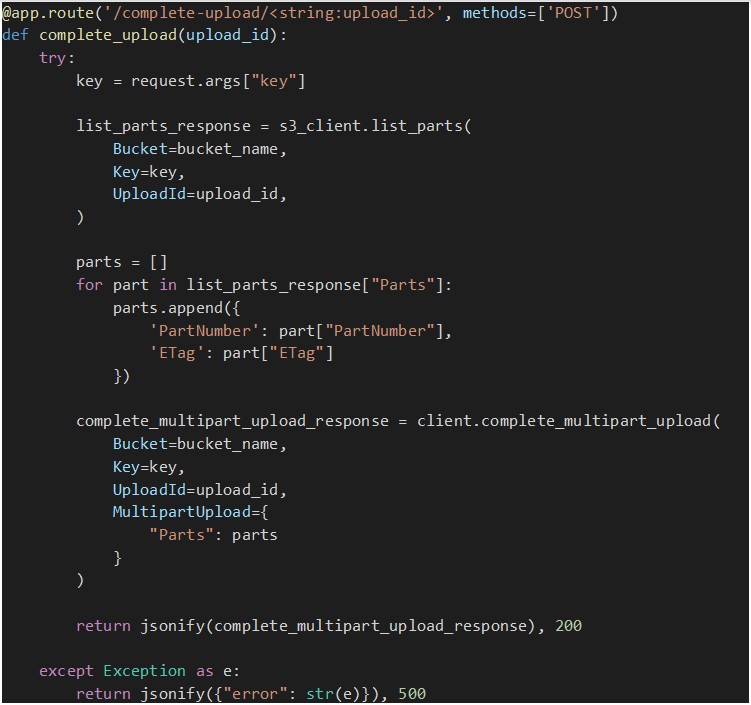
Quando todas as partes do ficheiro forem uploaded com êxito, este endpoint é chamado para concluir o multipart upload. Mas primeiro precisamos de ter um multipart upload em curso e toda a informação necessária sobre as partes uploaded até agora, como o ETag (um hash MD5 que representa os dados da parte) e os números das partes.
Para obter esses dados sobre as peças que já foram uploaded num determinado multipart upload, chamamos o método “list_parts” que recupera uma lista de dicionários, cada um representando uma peça uploaded, contendo detalhes como o número da peça e o ETag.
Assim que tivermos todas as informações sobre as partes, o método “complete_multipart_upload” é chamado para que o S3 reúna todas as partes no objeto final e o disponibilize no nosso bucket.
O que se segue é uma implementação do endpoint:
O lado front-end
Para implementar o lado web front-end usaremos o Dropzone.js, uma popular biblioteca JavaScript de código aberto que disponibiliza uma forma elegante e flexível de implementar uploads de ficheiros através da funcionalidade “arrastar e soltar” (drag-and-drop). Simplifica o processo de uploads de ficheiros, através de uma interface original e amigável, e lida com várias tarefas relacionadas com uploads, como a validação de ficheiros, a fragmentação de ficheiros grandes, e o suporte a uploads de vários ficheiros.
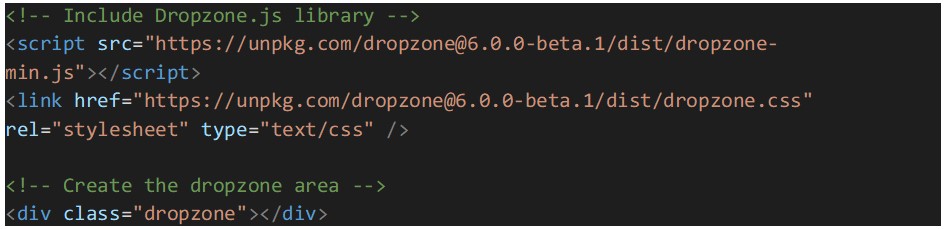
Vamos começar por configurar o Dropzone.js, incluindo-o no arquivo HTML. Podemos fazer download da biblioteca e referenciá-la localmente, ou usar um link CDN. Adicionalmente, um elemento HTML precisa de ser criado para atuar como a área de dropzone, onde os utilizadores podem arrastar e soltar ficheiros:
O passo seguinte é a configuração do Dropzone.js:
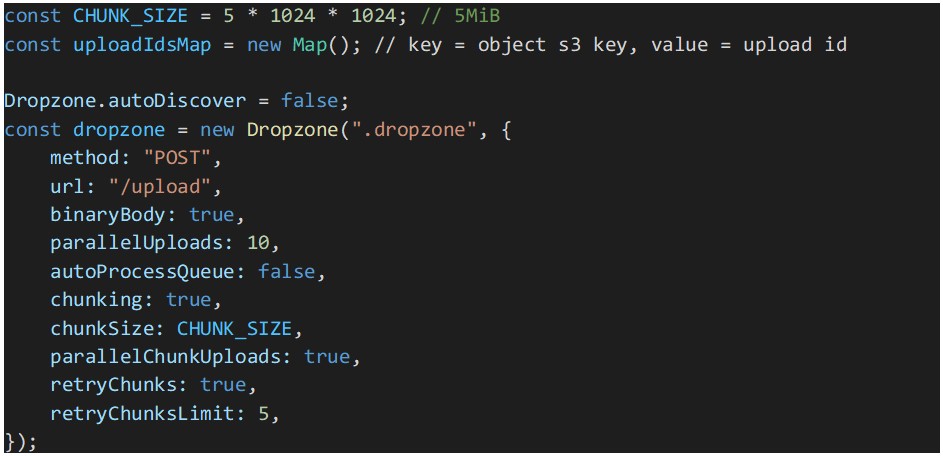
No trecho de código acima, será utilizada uma constante para o “chunk size” por parte do Dropzone, para dividir os ficheiros em partes ou pedaços de 5MiB. Note que o tamanho está em mebibytes e não em megabytes. Um mebibyte é um pouco maior que um megabyte e 5 MiB é o tamanho mínimo de parte suportado pelos envios de várias partes do AWS S3. O Dropzone vai dividir em pedaços todos os ficheiros iguais ou maiores que o valor “chunkSize”.
Para acelerar o envio de ficheiros, a paralelização do envio de partes está ativada. E para tornar os nossos multipart uploads mais resilientes, foram ativadas novas tentativas para os uploads que possam falhar.
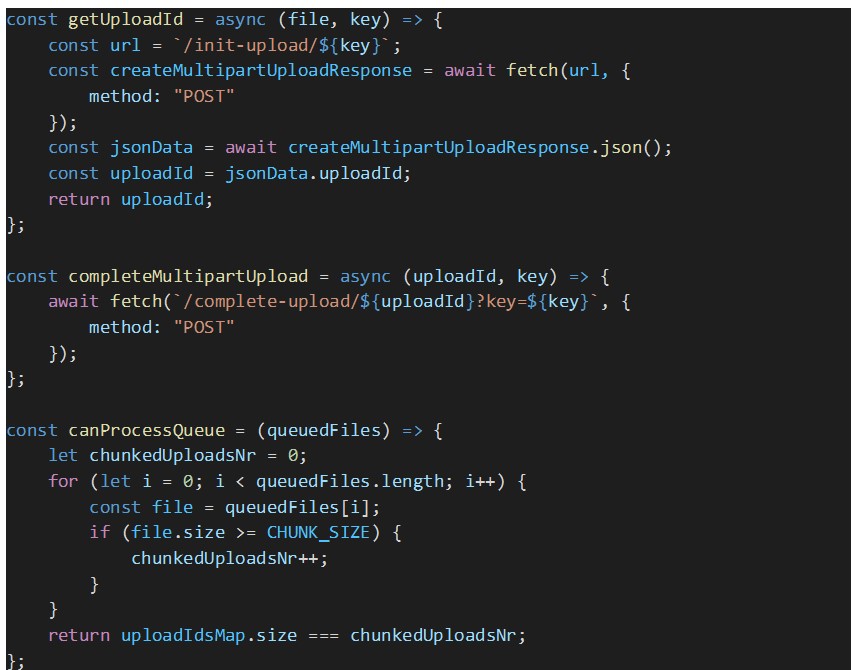
O processamento automático de ficheiros em fila de espera foi desativado porque precisamos de garantir que todos os ficheiros em espera obtêm o seu ID de multipart upload do AWS S3, antes de o Dropzone começar a processá-los. Caso contrário, existe o risco de que o upload de algumas partes dos ficheiros falhe devido à falta do ID de upload. Esses ID são armazenados no mapa “uploadIdsMap”.
Nota: certifique-se de que adia a inicialização do Dropzone até que a página seja uploaded. Isso pode ser conseguido, por exemplo, com uma Expressão de Função Imediatamente Invocada (IIFE).
Como precisamos que o Dropzone envie parâmetros personalizados em cada pedido de upload (por exemplo, o ID de upload de várias partes e a chave S3 do ficheiro que está a ser uploaded, entre outros dados), precisamos de substituir a opção “params” do Dropzone, conforme demonstrado abaixo:
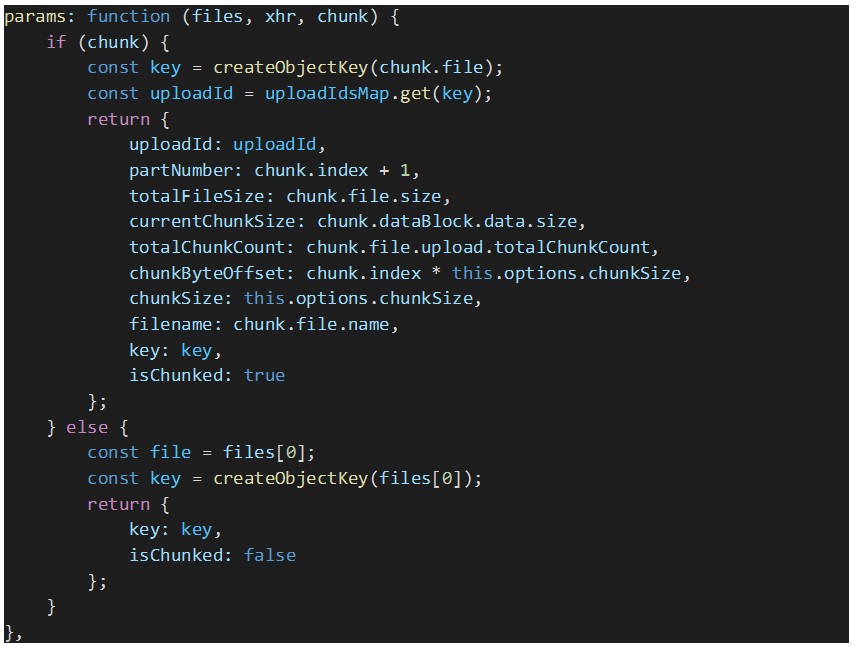
Para criar a chave de objeto S3 para o ficheiro uploaded, é utilizada a seguinte função:

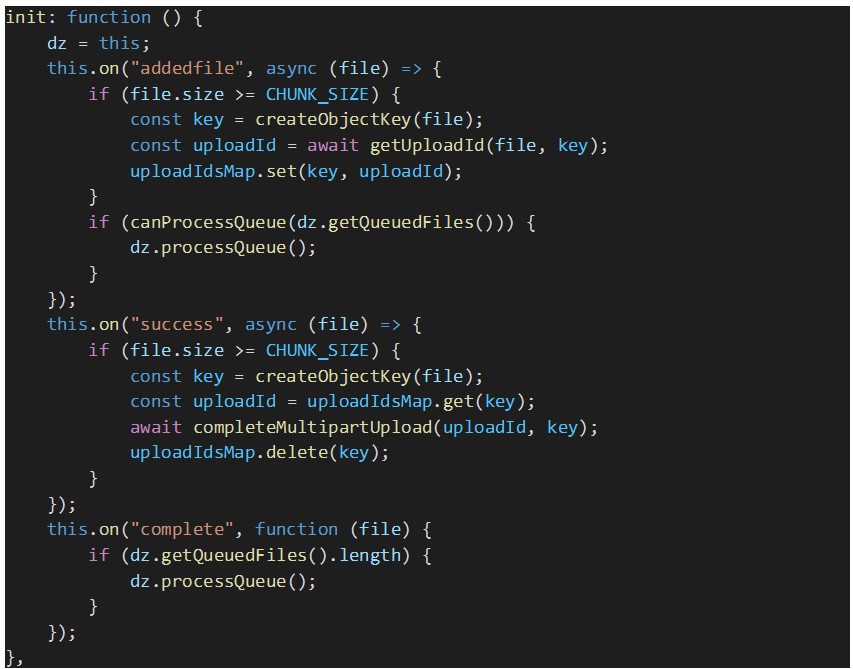
Por fim, temos de tratar os seguintes eventos do Dropzone:
- On file queued (addedFile): para cada ficheiro em espera é obtido um ID de multipart upload do AWS S3 a partir do back-end do proxy, ao chamar o endpoint “GET api/file/upload-id”. O ID de upload do ficheiro é armazenado no “uploadIdsMap” para ser enviado mais tarde pelo Dropzone em cada pedido de upload de um pedaço de ficheiro para o nosso back-end. Neste manipulador de eventos, esperamos até que todos os ficheiros em fila de espera sejam uploaded;
- On file upload success (success): quando um upload de partes é concluído com êxito, temos de concluir o multipart upload ao chamar o respetivo endpoint REST: “PUT /api/file/chunks/complete”;
- On file upload complete (complete): independentemente de o upload do ficheiro ter sido concluído com êxito ou com erro, temos de verificar se ainda existem ficheiros em fila de espera e, em caso afirmativo, temos de processar explicitamente a fila de espera para que o próximo lote de ficheiros, de tamanho igual à opção “parallelUploads”, seja processado.
Abaixo encontram-se os trechos de código que implementam os manipuladores de eventos do Dropzone descritos acima, juntamente com outras funções auxiliares usadas nesses manipuladores.
Conclusão
AWS S3 Multipart Upload é uma poderosa funcionalidade que melhora o desempenho, a fiabilidade e a flexibilidade do upload de grandes objetos para o Amazon S3. Ao dividir os objetos em partes mais pequenas, os developers podem tirar partido dos uploads paralelos e das capacidades de retoma, conduzindo a uploads mais rápidos e fiáveis.
Quer esteja a trabalhar numa aplicação com uso intensivo de dados, em armazenamento multimédia ou num sistema de distribuição de conteúdos, a compreensão e a implementação dos multipart uploads podem melhorar significativamente os seus fluxos de trabalho de gestão de dados S3, tornando-os uma ferramenta essencial no arsenal dos serviços de cloud AWS.
Descobre como implementar um website no Amazon S3 com o Terraform neste artigo.
